Vevee
Meter user AI usage, enforce caps, and generate personalized in-app copy.
Tagline
Meter AI usage. Stop leaks. Personalize upsells.
One SDK for AI metering, analytics, and copy.
Stop paying for uncapped AI before it ships.
Replace PostHog, quota logic, and prompt glue.
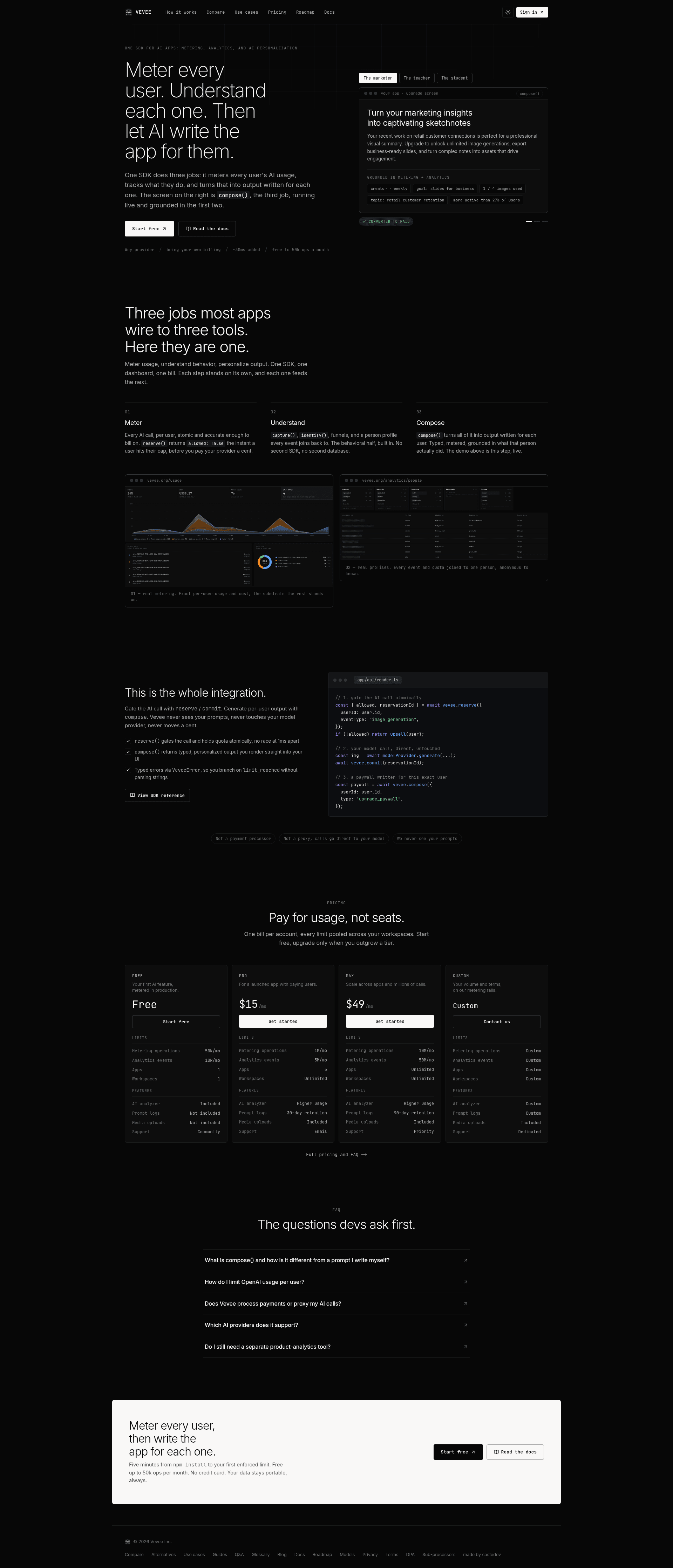
The metering layer for AI apps that also personalizes the product experience.
This is the clearest category-defining claim because Vevee combines billing-grade usage enforcement with analytics and in-app content generation, which most tools split across multiple systems.
The alternative to stitching together PostHog, billing rules, and a custom prompt pipeline.
The page explicitly says no second SDK, no second database, and no backend to build, so the strongest competitive frame is consolidation versus a DIY stack.
Stop paying for uncapped AI usage before the user hits your upsell screen.
The strongest pain-killer message is financial: `reserve()` can block spend instantly before the model call, which is more concrete than generic analytics or personalization claims.
Primary user
Indie AI app founder or full-stack engineer shipping a paid AI product who needs per-user limits and in-app upsells
ICP #1
Solo founder building a B2C AI writing or image app with a simple subscription tier
Pain
They need to stop power users from blowing through expensive model calls while also nudging free users to upgrade, but they do not want to wire up billing logic, analytics, and paywalls separately.
Why this solves
Vevee gives them one place to meter usage, block calls at the quota boundary, and generate an upgrade screen tailored to that exact user's behavior and usage history.
ICP #2
Founding engineer at a seed-stage B2B SaaS adding AI features to an existing workflow product
Pain
They have to figure out which users are consuming the most AI, who is close to limits, and how to explain overages without building a custom event pipeline.
Why this solves
Vevee's built-in `capture()`, `identify()`, funnels, and person profiles connect AI consumption to user-level behavior, making it easier to enforce entitlements and trigger targeted upgrade prompts.
ICP #3
Product-led growth manager at an AI education or productivity app
Pain
They want onboarding and upsell copy that reflects actual usage patterns, but current messaging is generic and disconnected from what users just did.
Why this solves
Vevee's `compose()` can render per-user onboarding, paywall, and upgrade copy grounded in metered usage and behavioral context, so messages can say things like 'You've already turned 3 dense meeting notes into clear visuals.'
Strengths
- +Very clear product mechanism: `reserve()`, `commit()`, `capture()`, and `compose()` are concrete and easy to understand.
- +Strong differentiation from proxies and payment processors; it explicitly says Vevee never sees prompts or money.
- +Excellent demo specificity: the example paywall copy shows the product outcome, not just the plumbing.
Weaknesses
- −The page is overloaded with concepts before it earns them; metering, analytics, personalization, billing, quotas, and compose() all hit at once.
- −The audience is ambiguous: it speaks to devs, founders, and marketers without clearly prioritizing one buyer.
- −The positioning leans too hard on infrastructure language and underexplains the business outcome, like higher conversion or lower AI COGS.
- −The comparison set is implied, not explicit enough; it never directly says why someone should pick Vevee over PostHog + custom quota logic + openai middleware.
- −Pricing is unusually low and may create trust issues for teams evaluating serious usage infrastructure; it needs stronger explanation of what scales and what is included.
Fix these
- Lead with one primary use case, likely per-user AI limits plus personalized upgrade screens, and move analytics/composition secondary.
- Add a direct comparison section against PostHog, Langfuse, and custom middleware showing exactly what Vevee replaces.
- Show more real-world examples for different app types: chat, image generation, document transformation, and workflow copilots.
- Quantify the business impact of `reserve()` and `compose()`: reduced model spend, higher upgrade conversion, less engineering time.
- Tighten the hero to one sharp promise and one proof point; right now it reads like a feature matrix rather than a buying argument.
Drop-in replacement copy
Headline
Stop AI spend leaks
Meter users, enforce caps, and write upgrade copy from real usage.
Block overages before you pay
Vevee checks usage with reserve() before the model call, so you can reject requests before provider cost happens. That means less wasted spend and cleaner limit handling.
See who is using AI
capture(), identify(), funnels, and person profiles show which users are driving usage and cost. You get product context, not just raw token counts.
Turn usage into better upsells
compose() generates per-user onboarding, paywalls, and upgrade prompts from real behavior. The message matches what the user actually did, so it feels specific instead of generic.
Ship with your existing model stack
Vevee works with OpenAI, Anthropic, Gemini, Mistral, Replicate, fal, and self-hosted models. Calls go direct from your app, so there is no prompt proxy to route through.
FAQ
Does Vevee proxy my prompts?
No. Your app calls the model provider directly. Vevee sits beside that flow for metering, analytics, and personalized copy.
How does quota enforcement work?
You call reserve() before the model request. If allowed is false, you stop before provider spend. After the request, you call commit() with the actual usage.
What if I already use PostHog or Amplitude?
You can keep them, but Vevee is built to handle AI-specific usage, limit enforcement, and per-user copy in one place. That removes the glue code around AI spend.
Can I use this for B2B SaaS AI features?
Yes. It is a good fit for any product that needs per-user AI limits, usage-based entitlements, or targeted upgrade prompts.
What do I get in the dashboard?
Usage, cost, active users, attributes, event charts, and person-level profiles so you can see what each user is doing and what it is costing you.
Shipped Vevee: an SDK that meters per-user AI usage, blocks spend before the model call, and writes personalized in-app copy from real usage. One SDK. No proxy. No extra backend. If you're shipping AI features, this saves real COGS.
Built Vevee because every AI app I see is duct-taped together: - model calls here - quotas in a spreadsheet - analytics in another tool - paywalls written by hand Vevee gives you reserve(), commit(), capture(), and compose() in one place.
The expensive bug in AI apps isn't bad prompts. It's letting the user hit the model first, then figuring out they were over quota. Vevee checks reserve() before provider spend, so you can say no before you pay.
User used 87 AI actions this week. Vevee can turn that into copy like: "You've turned 12 notes into drafts already. Upgrade to keep going." That's the point: metering data becomes the message.
If your stack is PostHog + billing rules + custom AI middleware, you already know the pain. Vevee replaces the boring parts: usage tracking, quota enforcement, funnels, profiles, and per-user copy. Less plumbing. More shipping.
Vevee is for AI apps that need to know: who used what what it cost when to stop what to say next That means metering, analytics, and personalized upgrade prompts without building the whole backend.
The easiest way to lose margin is uncapped AI usage. The easiest way to fix it is not a giant platform rewrite. It's reserve() before the call, commit() after, and a dashboard that shows who is burning tokens.
Free users don't upgrade from generic copy. They upgrade when the message reflects what they just did. Vevee's compose() uses real usage + behavior to generate the screen, so the upsell isn't random.
The clean flow is simple: 1. reserve() usage 2. if allowed, call OpenAI/Anthropic/Gemini/etc. 3. commit() actual usage 4. compose() the next screen from that context That's the whole product loop.
If you've built AI billing glue, you know it's never just billing. It's entitlements, analytics, upgrade prompts, limit handling, and explaining overages to users. Vevee is the boring layer I wanted to exist so teams could skip that work.
Angle: Per-user AI limits + personalized upsells
Most AI apps don't have a product problem. They have a meter problem. You ship a useful feature. Usage spikes. Costs creep up. Then someone asks for quotas, dashboards, upgrade prompts, and a better way to explain limits to users. That usually turns into three separate projects: - quota logic in the backend - analytics in another system - personalized copy hacked together later We built Vevee to make that one layer. It sits beside your model calls, not in front of them. You reserve usage before the call, commit it after, and generate per-user copy from the actual behavior you just observed. So the product can do things like: - block spend before provider cost happens - show who is close to their limit - render upgrade screens based on real usage, not generic templates If you're building a paid AI app, this is the part you end up building anyway. We just made it an SDK. Curious what people think is the hardest part here: metering, analytics, or the upsell copy?
Angle: Replace the DIY stack
The common AI app stack is getting weirdly bloated. PostHog for behavior. Custom logic for quotas. Billing tool for entitlements. Middleware for model calls. Some prompt pipeline for in-app copy. That works until it doesn't. Every layer has its own schema, its own events, its own edge cases. And somehow the one thing that matters most — per-user AI spend — is still stitched together by hand. Vevee tries to collapse that stack. capture() identify() reserve() commit() compose() One SDK for: - metering per user - enforcing limits before cost - understanding what users do - generating the next message they should see I like products that remove a whole category of glue code. This is one of those. If you are shipping AI features into an existing SaaS, would you rather keep the stack modular or collapse it into one layer?
Angle: Business outcome: lower COGS and higher conversion
The best AI infra products don't sound like infra. They sound like margin. If you can stop uncapped usage before the provider call, you reduce waste immediately. If you can see which users are burning the most AI, you can price and limit intelligently. If you can personalize the upgrade screen based on actual usage, you can improve conversion without inventing a separate personalization stack. That's the idea behind Vevee. It gives AI app teams one place to meter usage, track behavior, and generate per-user copy. Not because infrastructure is sexy. Because the business outcomes are real: - less model spend - less engineering time - better upgrade prompts - clearer user entitlements I think most founders underestimate how much time gets burned on this exact problem once AI becomes a real feature. If you've dealt with per-user AI limits, what did you build first: quotas, analytics, or paywalls?
No visuals for this kit yet.
Tagline
SDK for AI metering and personalized copy
Description
Meter per-user AI usage, stop overages before they cost money, and generate upgrade copy from real behavior. Vevee gives AI apps quotas, analytics, and personalized in-app messaging in one SDK.
Maker's first comment
I built Vevee because I kept seeing the same pattern in AI products: the feature ships, usage spikes, costs get messy, and then the team scrambles to bolt on quotas, analytics, and upgrade prompts after the fact. That usually means a custom backend project that nobody wanted to own. Vevee sits beside your model calls. You reserve usage before the provider spend happens, commit the actual usage after, and use that same data to drive analytics and personalized in-app copy. The goal was not to create another dashboard for the sake of it — it was to remove the glue code that every AI app ends up rebuilding anyway. I made it for indie founders and small product teams shipping paid AI features who want to know exactly who is using what, what it costs, and what to say next without wiring up three different systems.
Pinned maker comment
Would love feedback on the sharpness of the positioning: is the main value meter + block spend, or meter + personalized upsells? Also curious which examples matter most to you: chat, image, docs, or copilots.
Meta
Your AI app is bleeding margin
Hypothesis: founders shipping paid AI features need per-user quota enforcement before provider spend, not after. Vevee meters usage, blocks overages, and personalizes the upgrade screen from real behavior.
Google Search
AI usage metering SDK
Targeting developers searching for quota enforcement, AI analytics, or personalized upgrade prompts. Assumption tested: teams want one SDK for reserve/commit metering, user analytics, and per-user copy instead of stitching together PostHog plus custom middleware.
Reddit Promoted
Built my own AI quota stack first
Hypothesis: indie founders in AI communities will care more about stopping uncapped spend than fancy dashboards. Vevee handles per-user metering, limit checks before the model call, and personalized paywalls without proxying prompts.
Subreddits
r/SideProject
Show the build process and the exact problem: how to meter AI usage before provider spend and generate upgrade copy from the same data.
Rules: Share what you built and what you learned; avoid pure promo; include screenshots or code.
r/indiehackers
Write a founder story about replacing a messy AI stack: quotas, analytics, and upsells in one SDK.
Rules: Must be useful, story-first, and not a direct sales post.
r/microsaas
Frame Vevee as a small but high-leverage infrastructure layer for SaaS teams adding AI features.
Rules: Keep it practical; show a real use case and avoid hype.
r/EntrepreneurRideAlong
Post a progress update on launching a developer tool and invite feedback on positioning and pricing.
Rules: Prefer transparent journey posts over launches; engage in comments.
r/SaaS
Focus on reducing COGS and improving conversion for AI-enabled SaaS products.
Rules: Substance over promotion; don't make it a link dump.
Communities
Publish a build log and a teardown of the AI quota problem; reply to every comment with concrete implementation details.
Submit a technical write-up about reserve/commit metering and why AI apps need to block spend before the call.
Join model/app-builder discussions and offer implementation help on usage metering and limit handling without dropping links first.
Cold outreach template
Hey {firstName} — saw {context} and thought of Vevee. It meters per-user AI usage, blocks overages before provider spend, and can generate personalized upgrade copy from the same usage data. If you want, I can show you the API in 5 minutes and you can tell me if it solves the quota/prompt mess you have right now.
Product Hunt timing
Launch on Tuesday at 12:01 AM Pacific time. That gives you the full PH day starting early for US builders while still catching Europe in the morning and avoiding weekend noise; this ICP is developer-heavy, so weekday discovery works better than a Friday drop.
Indie Hackers post ideas
- 01I replaced PostHog + custom quota logic with one SDK
- 02How reserve/commit metering saves money before the model call
- 03What personalized AI upgrade screens do to conversion
Competitor alternatives
Current tone of voice
Technical, founder-to-developer, and slightly playful; for example, 'Then let AI write the app for them.' and 'One SDK for AI apps: metering, analytics, and AI personalization.'
Your kit is ready. Sign up free to unlock, takes 10 seconds.
7 more X posts · 2 LinkedIn · Product Hunt copy · ad hooks · 100-user playbook · landing critique